DRP – Disaster Recovery Plan
En quelques mots
Un plan de reprise d’activité (Disaster Recovery Plan – DRP) a pour objectif de planifier le rétablissement, dans les meilleurs délais, d’une infrastructure informatique. Il vise à permettre la reprise opérationnelle des services en cas de sinistre. Le plan de reprise d’activité se distingue du plan de continuité d’activité.
- Le plan de reprise d’activité se caractérise par son approche technique de la reprise suite à un sinistre informatique.
- Le plan de continuité d’activité est un document générique et surtout stratégique, planifiant et détaillant les types d’actions pour gérer une catastrophe ou un sinistre grave.
Le plan de reprise d’activité doit permettre un basculement vers une infrastructure informatique « alternative » dédiée à la survie du business ou de l’activité. Les plans de reprise d’activité sont conçus et évoluent en fonction des besoins du business.
RTO et RPO
Tout DRP doit être construit sur la base des deux notions suivantes :
RTO : La Durée maximale d’interruption admissible (Return Time on Objective – RTO)
RPO : La Perte de Données Maximale Admissible (Recovery Point Objective – RPO)
Toute entité désirant concevoir un plan de reprise d’activité devra initialement définir les buts de sécurité en fonction de ces besoins élémentaires (Voir gestion des risques).
RTO
Le RTO définit le temps maximal acceptable durant lequel une ressource informatique peut se trouver indisponible suite à un sinistre.
Ce temps d’interruption prend en compte :
-
Le délai pour la détection de l’incident,
-
Le temps nécessaire pour décider de lancer la procédure de reprise,
-
Le délai de mise en œuvre du plan de reprise d’activité,
-
Configuration du réseau,
-
Restauration des données,
-
Contrôle de la qualité et du niveau de service (mode dégradé ou pleinement fonctionnel).
-
Le RPO définit la quantité maximale de données qui peut être perdue suite à un sinistre informatique. Cette valeur constitue la différence entre la dernière sauvegarde et l’incident. Elle est exprimée dans la plupart des cas en minutes/heures.
Schématisation Incident
Le schéma ci-dessous fait état de l’évolution du niveau de service en fonction d’un incident. Il a pour objectif de modéliser les notions de RPO et de RTO pour montrer leur différence, mais aussi leur complémentarité.
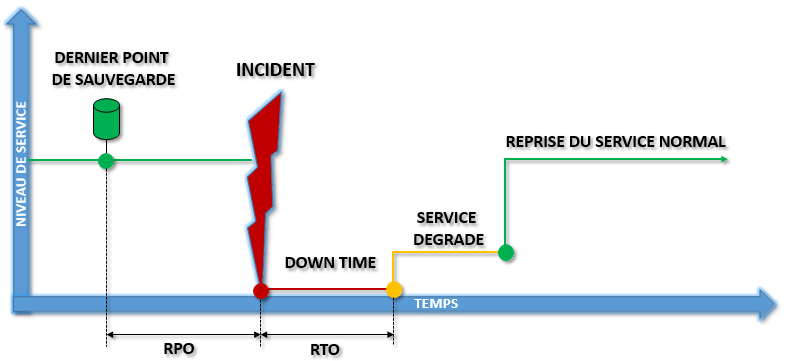
En fonction de l’importance du sinistre, un plan de reprise doit pouvoir prendre en compte de nombreux scénarios de reprise d’activité en allant d’actions simples à des mécanismes complexes.
Concrètement, une entreprise s’expose quotidiennement à de nombreux risques, pouvant entrainer un sinistre et justifiant l’activation d’un plan de reprise. Exemples :
- Une infection virale ayant pour nécessité de restaurer un système,
- Une panne matérielle nécessitant le remplacement des éléments défectueux,
- La destruction de fichiers réclamant l’activation d’un moyen de restauration,
- Une catastrophe naturelle ou accident justifiant l’activation d’un site informatique de secours.
Les exemples précédents sont variables sur les notions de RPO et de RTO et démontrent qu’un plan de secours doit reposer sur différentes technologies afin de répondre à une multitude de sinistres.
- Sauvegardes,
- Matériels de remplacement,
- Moyens informatiques redondants répondant à une exigence de haute disponibilité,
- Site de secours.
Globalement, la mise en œuvre d’un plan de reprise d’activité s’articule autour des 12 points clés.
Réussir un DRP-12 points clés
1. Inventaire des actifs informatiques.
Tout actif faisant partie du système informatique de l’infrastructure doit être clairement identifié et répertorié dans une base de données de type CMDB (Configuration Management DataBase).
- Connectique et réseau: routeurs, switches, racks, etc.
- Matériels partagés: serveurs, stockage, imprimantes, etc.
- Matériel individuel: stations de travail, ordinateur portables, smartphones, etc.
- Salle serveurs, salle de stockage des sauvegardes, etc.
- etc.
La base de données doit impérativement être tenue à jour. Il est conseillé d’ajouter un champ permettant d’indiquer la date de mise en service du matériel afin d’en détecter l’usure et l’obsolescence.
2. Inventaire et cartographie des données et applications
Chaque base de données ainsi que chaque application doit être clairement identifiée dans une base de données commune avec celle des actifs informatiques afin de mettre en évidence les relations entre actifs physiques et actifs logiques.
À tout moment, cette base de données doit permettre de répondre à la question suivante : « Sur quel serveur est hébergée telle application ? »
À ce stade, il est tout aussi important de cartographier l’infrastructure informatique sous la forme d’un « plan » afin de modéliser les relations salle serveurs - serveurs – stockage – flux – applications – bases de données.
3. Classification
La classification des actifs doit être l’aboutissement d’un processus impliquant les responsables métier (commerce, comptabilité, …), le responsable informatique et un membre de la direction.
L’objectif est de décider quelles sont les applications nécessaires au bon fonctionnement de « l’entreprise ». Il est conseillé d’utiliser l’échelle de valorisation suivante :
-
Application vitale :
- La perte définitive de cette application et des données associées condamne l’entreprise à la cessation d’activité ou à de très graves difficultés.
- La perte temporaire de cette application et des données associées provoque une perte d’exploitation significative.
-
Application critique :
- La perte définitive de cette application et des données associées provoque une interruption de service plus ou moins longue et force une partie du personnel au chômage technique.
- La perte temporaire de cette application et des données associées provoque une perte d’exploitation mineure.
-
Application standard :
- La perte définitive de cette application et des données associées n’impacte que très peu l’activité de l’entreprise.
- La perte temporaire de cette application et des données associées est quasi insignifiante.
Lorsque chaque application est classée, le responsable informatique doit appliquer à chaque ressource informatique le même niveau de classification. Pour des ressources partagées, ce sera toujours la classification la plus critique qui sera prioritaire.
Ainsi grâce à cette classification, le responsable informatique est en mesure de préparer le plan de reprise d’activité puisqu’il connaît les priorités business.
4. Analyse des besoins vitaux liés au business / Priorisation / Risques
Sur la base des inventaires et de la classification des actifs, le responsable informatique établit un document présentant les règles de priorité de redémarrage des services.
Ce document doit être validé par un membre de la direction.
Pour sa part, le comité de direction doit mandater un expert afin de traiter tous les risques auxquels « l’entreprise » est exposée (analyse de risques).
Le critère de réussite de l’étape 4 est une connaissance exhaustive de l’environnement informatique de « l’entreprise » et des risques auxquels elle est exposée.
5. Conception des seuils RPO/RTO
Lorsque la précédente étape est validée, le responsable informatique, ainsi que les responsables métier et un membre de la direction se réunissent pour déterminer les RPO et RTO.
Cette étape est déterminante, car elle confronte les capacités informatiques à faire face à la résolution d’un sinistre par rapport aux besoins et aux risques de l’entreprise.
Les objectifs attendus :
- Les responsables métier et le membre de la direction doivent :
- Fixer la durée maximale d’interruption admissible (RTO) par application dans le cadre d’un incident impliquant une seule application.
- Fixer la durée maximale d’interruption admissible (RTO) dans le cadre d’un sinistre impliquant la totalité de l’entreprise. Dans ce point, l’utilisation d’un mode dégradé doit aussi être discutée.
- Fixer la perte de données maximale admissible (RPO)
- Le responsable informatique doit :
- Confronter sa vision à celle du business afin de fournir les meilleures explications et trouver un compromis concernant les capacités de reprise informatique.
- Négocier avec la direction pour obtenir des moyens techniques et financiers répondant aux besoins du business.
6. Étude des solutions techniques et financières
Sur la base des résultats des négociations issus de l’étape 5, le responsable informatique doit étudier et proposer des solutions techniques adaptées aux besoins du business.
Son travail doit se focaliser sur deux axes :
- Solutions dédiées au RPO,
- Solutions dédiées au RTO.
Aujourd’hui, il existe de nombreuses solutions permettant de répondre aux besoins du business, mais les coûts peuvent très fortement varier. Plus les seuils de RTO / RPO sont faibles, plus les coûts sont élevés.
7. Validation
Lorsque le responsable informatique a terminé l’étude sur les faisabilités techniques, celui-ci présente un rapport aux membres de la direction sur lequel figurent les choix liés aux exigences du business et aux contraintes financières et techniques.
Dans la mesure où des investissements doivent être effectués pour développer ou maintenir le plan de reprise d’activité, le rapport doit faire mention de cette nécessité.
Sur validation de cette étape, le responsable informatique implémente les solutions techniques dédiées au plan de reprise d’activité.
8. Implémentation
En fonction du budget, des ressources et des objectifs, le responsable informatique initie l’implémentation des solutions techniques en prenant en compte les délais imposés par les membres de la direction. Un calendrier comprenant des échéances devra avoir été validé préalablement par la Direction et le responsable informatique.
9. Rédaction des procédures
Lorsque l’ensemble des solutions techniques est fonctionnel, les personnes en charge de leur maintenance doivent rédiger des procédures décrivant leur mise en œuvre technique. Celles-ci doivent être testées par une tierce personne.
Pour des raisons de sécurité, ces procédures doivent être stockées dans environnements physiquement distincts. Elles doivent être sécurisées contre toutes modifications ou altération et protégées afin que seules les personnes ayant le besoin d’en connaître aient accès.
10. Rédaction du DRP et des conditions de déclenchement
Le responsable informatique qui est de fait le responsable de la maintenance du plan de reprise d’activité doit s’assurer que les processus techniques sont protégés, disponibles et à jour.
À l’issue, il débute la rédaction du plan de reprise d’activité en se basant sur différents scénarios et en n’omettant pas d’indiquer pour chacune des situations les conditions de déclenchement et les processus techniques liés.
Concrètement, un scénario met en scène un risque auquel « l’entreprise » est exposée et présente la solution pour rétablir la situation en respectant les RPO et RTO.
Un scénario doit se construire « simplement ». Voici deux exemples de scénario.
Scénario 1 : Exploitation d’une faiblesse wifi par une entité malveillante
=> L’analyse de risques a préalablement détectée une vulnérabilité sur l’infrastructure wifi donnant accès au réseau interne. La clé WPA n’a pas été changée depuis 2 ans, le mot de passe est faible et il est connu de tous le personnel et de « personnes » ne faisant plus partie des effectifs.
Thème général : Un hacker est mandaté par la concurrence pour altérer les données clients.
L’attaque :
Un hacker, motivé par l’appât du gain, dispose de ressources informatiques et de connaissances approfondies pour exploiter des vulnérabilités techniques du réseau informatique. Il exploite plus particulièrement la liaison wifi faiblement protégée et altère le serveur hébergeant les informations comptables des clients en impactant l’intégrité des données. Il change volontairement des informations comptables clients (débits / crédits / encours).
Composantes du scénario :
- Sources de la menace : Un concurrent utilise un moyen déloyal pour altérer les systèmes informatiques de son « rival ».
- Menace : Un hacker pénètre le réseau via une liaison wifi pour altérer des données. Il dispose de moyens et de connaissances.
- Vulnérabilités exploitées : Wifi faiblement protégé (clé WPA faible et connue).
- Support informatiques impactés : Réseau + serveur.
- Eléments finaux impactés : Données financières clients (Débits et Crédits).
- Effet recherché par le hacker : Provoquer une perte d’intégrité.
- Impact potentiel sur l’organisation : Perte financière – Perte de confiance des clients – Discrédit public.
Eléments à tester :
- Sommes-nous en mesure de détecter l’attaque :
- En direct ?
- A posteriori suite à une analyse de logs ?
- Seulement après qu’un client manifeste une incohérence ?
- Sommes-nous en mesure de respecter le RTO ?
- Sommes-nous en mesure de respecter le RPO ?
Contre-mesures / solutions techniques à tester :
- Système de surveillance des données sensibles et réseau.
- Existe-t-il une génération d’alerte en cas :
- d’utilisation du wifi en dehors des heures de travail,
- de consultation de données clients en dehors des heures de travail,
- …
- Tous les moyens de restauration permettant la récupération de données conformément au RPO.
- …
Scénario 2 : Incendie majeur en salle serveurs
=> L’analyse de risques a préalablement détectée plusieurs vulnérabilités dans la salle serveurs hébergeant les données vitales de l’entreprise. Il n’y a pas de détecteur de fumée, il n’y a aucun moyen d’extinction automatique d’un incendie et le système de sauvegarde est hébergé dans la même salle que les serveurs.
Thème général : Un court-circuit provoque la destruction totale de la salle serveurs.
L’incident :
Le dirigeant de l’entreprise a décidé de lancer des travaux de rénovation électrique. A la veille du week-end, un ouvrier travaillant dans le tableau électrique se situant dans la salle serveurs, néglige des raccordements sur les disjoncteurs. Dans la nuit de vendredi à samedi une surchauffe due à un faux contact, provoque un incendie détruisant l’entièreté des moyens informatiques. Facteur aggravant, les systèmes de sauvegarde sont dans la même salle serveurs. Toutefois, une copie des sauvegardes est placée mensuellement dans un coffre-fort d’un bâtiment annexe.
Composantes du scénario :
- Sources du problème : Un incendie
- Menace : Négligence d’un ouvrier
- Vulnérabilités : Aucun système de détection de fumée et aucun moyen d’extinction d’incendie
- Support informatiques impactés : Réseau + serveur + systèmes de sauvegarde
- Conséquence immédiate : Perte de disponibilité
- Impact potentiel sur l’organisation : Perte d’exploitation – perte financière
Eléments à tester :
Sur la base de la sauvegarde hébergée dans le coffre-fort du bâtiment annexe :
- Sommes-nous en mesure de respecter le RTO ?
- Sommes-nous en mesure de respecter le RPO ?
Contre-mesures / solutions techniques à tester :
- Pour le redémarrage des services informatiques sommes-nous en
mesure :
- D’utiliser une salle serveurs provisoire ou de remplacement ?
- Les ressources humaines sont-elles disponibles et ont elles les compétences pour reconstruire l’infrastructure ?
- …
- Le fournisseur est-il en mesure de respecter le SLA (s’il existe) pour la livraison de matériels de remplacement ?
- …
11. Tests
Le plan de reprise d’activité doit être testé régulièrement. Sur la base du document présentant les différents scénarios, le responsable informatique met en scène un sinistre afin de tester les capacités techniques et organisationnelles à reprendre l’activité.
Un rapport doit être rédigé à la fin de chaque exercice. Celui-ci est à destination des membres de la direction et présente les points positifs et négatifs du test de reprise d’activité. En conclusion, le responsable informatique préconise des améliorations ou recommandations si les RPO et RTO n’ont pas été respectés.
12. Mises à jour des procédures et du DRP
Le responsable informatique doit veiller à ce que les procédures et le plan de reprise d’activité soient à jour. Lors d’un changement majeur dans l’infrastructure informatique, le cycle des douze points clés doit être relancé.